聯(lián)想上海公司注冊資本激增3900%至4億港幣,技術(shù)服務(wù)戰(zhàn)略布局深化
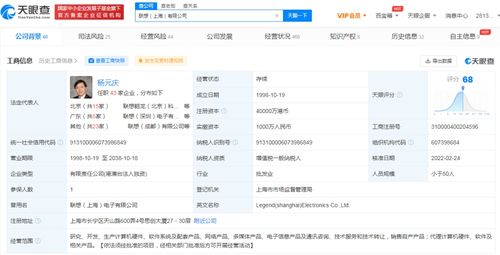
聯(lián)想集團(tuán)旗下的聯(lián)想(上海)信息技術(shù)有限公司(以下簡稱“聯(lián)想上海公司”)完成工商變更,注冊資本從原有的約1000萬港幣大幅增至4億港幣,增幅高達(dá)3900%。這一顯著變動(dòng)不僅體現(xiàn)了聯(lián)想對(duì)上海乃至長三角區(qū)域市場的高度重視,更釋放出其加速向技術(shù)服務(wù)型企業(yè)轉(zhuǎn)型的強(qiáng)烈信號(hào)。
此次增資行為在資本層面是一次規(guī)模可觀的“加碼”。注冊資本的大幅提升,意味著聯(lián)想上海公司的資金實(shí)力、抗風(fēng)險(xiǎn)能力以及對(duì)外業(yè)務(wù)承接能力將得到實(shí)質(zhì)性增強(qiáng)。在商業(yè)運(yùn)營中,更高的注冊資本往往能提升合作伙伴的信心,有利于公司在重大項(xiàng)目投標(biāo)、技術(shù)合作及高端人才引進(jìn)等方面占據(jù)更有利的位置。聯(lián)想選擇此時(shí)對(duì)上海公司進(jìn)行巨額增資,無疑是為其未來在該區(qū)域的業(yè)務(wù)拓展奠定了堅(jiān)實(shí)的財(cái)務(wù)基礎(chǔ)。
更為關(guān)鍵的是,此次增資與“技術(shù)服務(wù)”這一核心業(yè)務(wù)方向緊密關(guān)聯(lián)。聯(lián)想集團(tuán)持續(xù)推進(jìn)“端-邊-云-網(wǎng)-智”新IT技術(shù)架構(gòu)的落地,其戰(zhàn)略重心已從傳統(tǒng)的硬件設(shè)備制造商,轉(zhuǎn)向涵蓋智能設(shè)備、基礎(chǔ)設(shè)施和方案服務(wù)的全方位科技公司。上海作為中國的經(jīng)濟(jì)、金融、科技和創(chuàng)新中心,匯聚了豐富的技術(shù)人才、創(chuàng)新資源和高端客戶群,是發(fā)展高附加值技術(shù)服務(wù)的理想陣地。
聯(lián)想上海公司注冊資本激增,資金很可能將重點(diǎn)投向以下幾個(gè)技術(shù)服務(wù)領(lǐng)域:
- 行業(yè)智能解決方案:針對(duì)金融、制造、教育、醫(yī)療等行業(yè),提供基于大數(shù)據(jù)、人工智能和物聯(lián)網(wǎng)的定制化數(shù)字化轉(zhuǎn)型方案。
- 云服務(wù)與數(shù)據(jù)中心業(yè)務(wù):強(qiáng)化本地化部署和混合云服務(wù)能力,滿足企業(yè)和政府客戶對(duì)數(shù)據(jù)安全與算力的多元化需求。
- 研發(fā)創(chuàng)新投入:在上海設(shè)立或加強(qiáng)研發(fā)中心,聚焦邊緣計(jì)算、人工智能、5G等前沿技術(shù)的應(yīng)用開發(fā)。
- 服務(wù)生態(tài)構(gòu)建:擴(kuò)大技術(shù)咨詢、運(yùn)維支持、系統(tǒng)集成等服務(wù)團(tuán)隊(duì),打造更完善的技術(shù)服務(wù)交付與支持體系。
從市場環(huán)境看,全球數(shù)字化、智能化進(jìn)程加速,企業(yè)對(duì)專業(yè)化技術(shù)服務(wù)的需求呈現(xiàn)爆發(fā)式增長。聯(lián)想通過此次增資,可以更靈活、更積極地參與上海及長三角地區(qū)的智慧城市、企業(yè)數(shù)字化改造、新基建等項(xiàng)目競爭,抓住產(chǎn)業(yè)升級(jí)帶來的歷史性機(jī)遇。
聯(lián)想上海公司注冊資本高達(dá)3900%的增幅,絕非簡單的工商信息變更。它是聯(lián)想集團(tuán)深化區(qū)域戰(zhàn)略布局、強(qiáng)化技術(shù)服務(wù)核心競爭力的一個(gè)關(guān)鍵舉措。這預(yù)示著聯(lián)想正以充足的“彈藥”,在上海這一戰(zhàn)略高地,開啟以技術(shù)和服務(wù)驅(qū)動(dòng)新一輪增長的重要篇章。聯(lián)想在上海的技術(shù)服務(wù)業(yè)務(wù)如何落地生根、開花結(jié)果,值得業(yè)界持續(xù)關(guān)注。
如若轉(zhuǎn)載,請(qǐng)注明出處:http://www.qxfg.net.cn/product/74.html
更新時(shí)間:2026-06-18 12:09:52